
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 그래프탐색
- 2178
- 스케일아웃
- 트리맵
- findById
- 프로젝트
- 산업은행청년인턴
- 가상 면접 사례로 배우는 대규모 시스템 설계 기초
- 임베디드타입
- 산업은행it
- 코테
- 외래키제약조건위반
- 프로그래머스
- 파이널프로젝트
- 운영체제
- 구현
- 백준
- SpringBatch
- 폰켓몬
- DB replication
- 컴퓨터구조
- 해시
- Spring JPA
- CPU스케줄링
- fatch
- flyway
- BFS
- 트리셋
- JPA
- CS
- Today
- Total
나 JAVA 봐라
[컴퓨터 구조] 명령어 본문
전공 수업 때, CS를 분명히 공부했음에도 실제로 어떻게 적용되며 어떻게 각 계층이 이어지는 것인지에 대해 유기적으로 이해하지 못했었다. 이번에 강의를 듣고 정리하는 과정을 통해 확실하게 내 지식으로 가져가보고자 한다 !
강의는 패스트캠퍼스의 '현실 세상의 컴퓨터공학 지식 with 30가지 시나리오' 를 수강했다.
https://fastcampus.co.kr/dev_online_newcomputer
현실 세상의 컴퓨터공학 지식 with 30가지 실무 시나리오 초격차 패키지 Online. | 패스트캠퍼스
국내유일, 77시간 분량의 개발자를 위한 한 번에 끝내는 컴퓨터공학 (CS 지식) 강의를 확인하세요. 자료구조,알고리즘부터 디자인패턴, 클린코드까지 ! CS지식의 이론~실습뿐 아니라, 실제 실무에
fastcampus.co.kr
소스코드에서 명령어로
컴퓨터는 소스 코드(java, C/C++, ...) 를 곧장 이해할 수 있을까? -> 아니다 !
소스 코드는 실행되기 전 명령어(+데이터)로 변환되어서 실행된다.
컴퓨터는 '명령어'를 이해한다.
- 소스 코드: 고급 언어, 사람이 이해하기 쉬운 언어
- 명령어와 데이터: 저급 언어, 컴퓨터가 이해하기 쉬운 언어
=> '고급 언어'로 작성된 소스 코드는 내부적으로 '저급 언어'로 구성된 명령어와 데이터로 변환되어 실행된다.
저급 언어의 두 종류
- 기계어 : 컴퓨터가 '직접' 이해하는 언어 (이진수)
- 어셈블리어 : 기계어 -> 사람이 이해하기 조금 더 쉬운 언어
=> CPU, 소프트웨어 등에 따라서 기계어, 어셈블리어가 달라질 수 있다.


고급 언어에서 저급 언어로 변환되는 대표적 방식
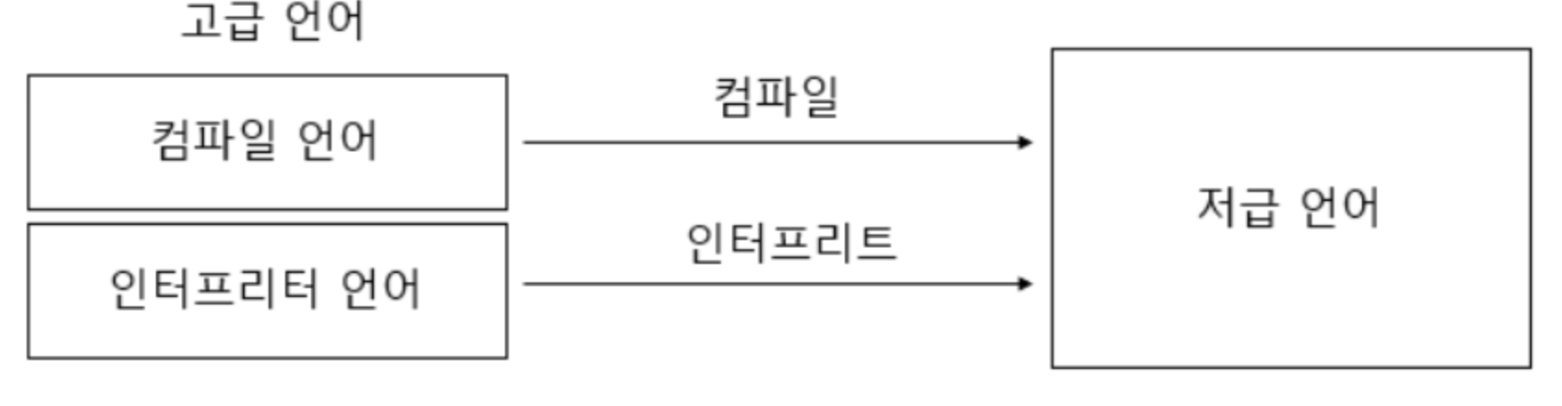
- 컴파일
- 소스 코드 전체가 컴파일러에 의해 검사, 목적 코드로 변환
- C/C++, Rust
- 컴파일러 종류 : gcc, clang, Visual Studio, ...

- 인터프리트
- 소스 코드 한 줄씩 인터프리터에 의해 검사, 목적 코드로 변환
- Python, JavaScript
=> 컴파일/ 인터프리트 성능 비교 : 컴파일 된 상황이라면 컴파일 방식이 더 빠르다. 인터프리터는 한 줄씩 검사하고 변환하기 때문이다. 그래서 n번째 줄에 이상이 생기면, n-1번까지는 실행된다.
=> 소스 코드가 저급 언어로 변환되는 대표적인 방식일 뿐 컴파일 방식과 인터프리트 방식은 칼로 자르듯 구분되는 개념은 아니다. 컴파일 언어의 특성과 인터프리트 언어의 특성을 모두 갖춘 언어(ex. java) 도 있다.
명령어의 구조
명령어

명령어는 크게 명령의 대상, 명령의 동작으로 이루어져 있다.


실제 어셈블리어를 보면 연산 코드 + 오퍼랜드로 구성되어 있다.
즉 명령어는 '오퍼랜드로 연산 코드를 수행하라' 는 구조로 이뤄져 있다.
- 오퍼랜드(operand) : 명령어를 수행할 대상
- 대상(데이터)이 직접 명시되기도 하고, 대상의 위치(레지스터 이름, 메모리 주소)가 명시되기도 함
- 연산 코드(op-code) : 오퍼랜드로 수행할 동작

위의 이미지에서 알 수 있듯, 오퍼랜드의 갯수는 유동적이다.
오퍼랜드가 많아질 경우, 명령어가 두 줄 이상으로 처리될 수도 있다.



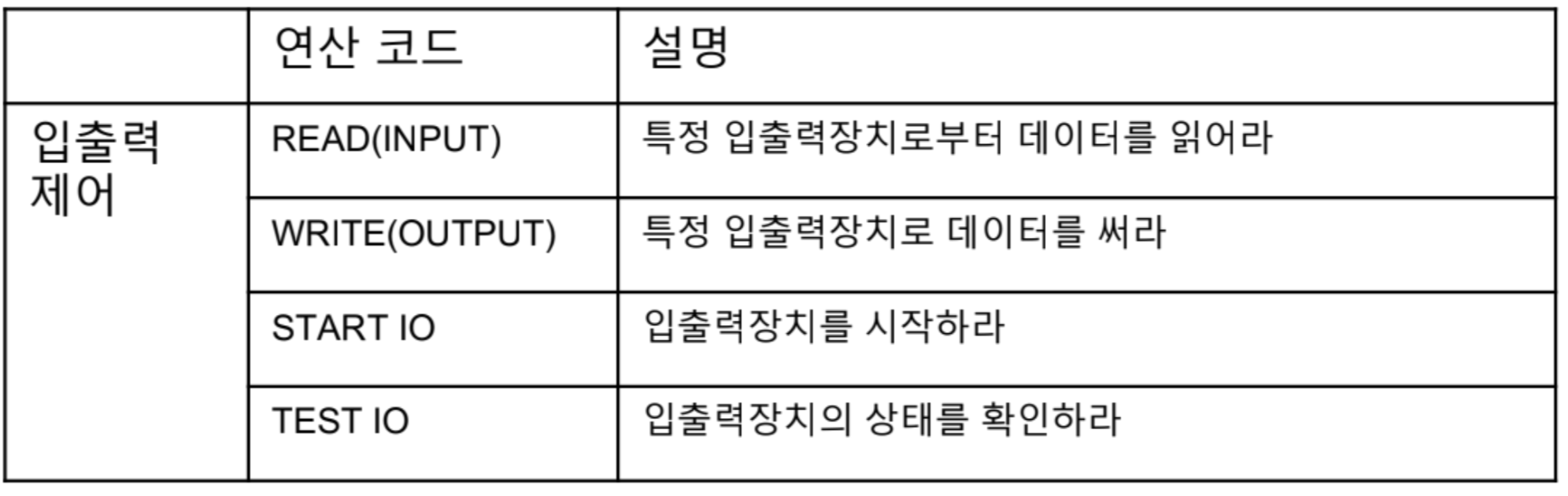
CPU에 따라 명령어가 달라지지만, 위의 연산 코드는 공통적으로 쓰인다.
- CALL/ RETURN : 함수 호출/ 반환 시에 사용된다. 특정 주소에 있는 함수를 호출할 때 CALL, 함수 실행 끝났으면 RETURN 해서 다시 원래의 주소로 돌아간다.
주소 지정
주소 지정이란? 연산 코드의 대상이 되는 데이터를 어떻게 찾을 것인지에 대한 것이다. 즉 오퍼랜드에 '주소'가 담겼을 경우에 대한 내용이다.
왜 데이터를 직접 명시하지 않고 위치를 명시하는 것일까?
- 명령어의 길이가 한정되어 있기 때문이다.

주소 지정에 대해 알아보기 앞서, 알아야할 용어 두 개가 있다. 유효 주소와 주소 지정이다.
유효 주소
- 연산 코드에 사용할 데이터가 저장된 위치, 즉 연산의 대상이 되는 데이터가 저장된 위치
주소 지정
- 유효 주소를 찾는 방법
- CPU 마다 차이가 있다.
이제 주소 지정 방식에 대해 알아보자
- 즉시 주소 지정
- 직접 주소 지정
- 간접 주소 지정
- 레지스터 주소 지정
- 레지스터 간접 주소 지정
즉시 주소 지정
- 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시
- 가장 빠른 주소 지정 + 데이터 크기에 제한

직접 주소 지정
- 오퍼랜드 필드에 유효 주소(연산에 사용될 데이터가 저장된 메모리 주소) 명시
- 오퍼랜드 필드로 표현 가능한 메모리 주소 크기에 제한 -> 한번 메모리에 접근한다. 메모리 주소 크기가 크기 때문에 할당된 메모리 주소로 주소를 다 나타낼 수 없는 문제가 있다. (그래서 간접 주소 지정 등장)
- CPU가 메모리에 접근하는 속도는 CPU가 레지스터에 접근하는 속도보다 매우 느리다. 그렇기 때문에 레지스터로 처리할 수 있는 것은 레지스터에서 처리하는 것이 좋다.

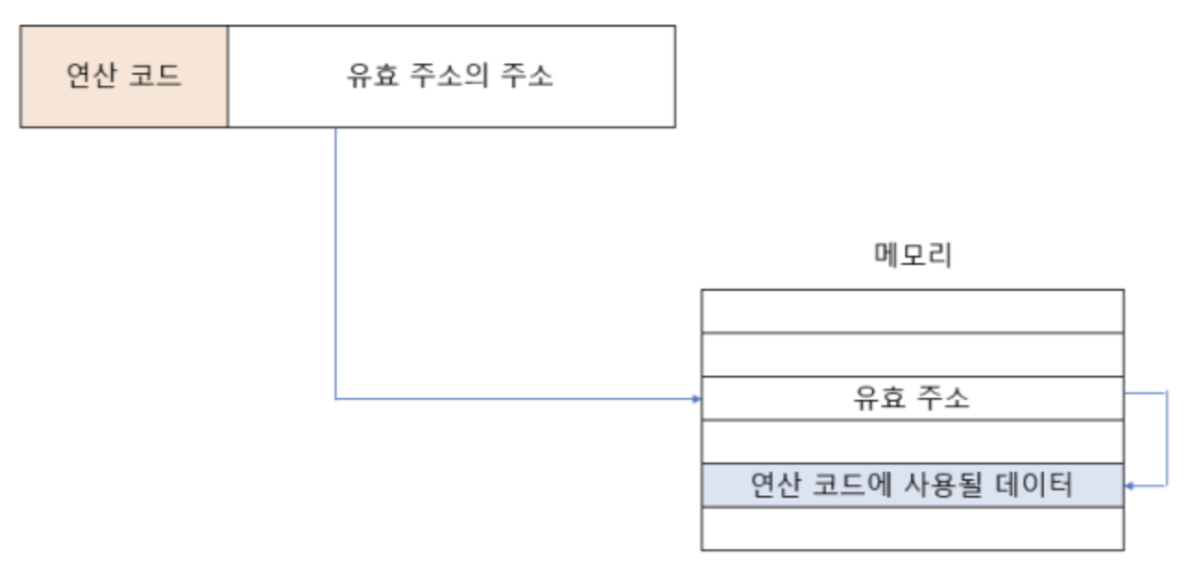
간접 주소 지정
- 오퍼랜드 필드에 유효 주소의 주소 명시
- 유효 주소 크기에 제한은 없으나, 속도가 비교적 느림 -> 메모리에 '두 번' 접근하기 때문에 느림
레지스터 주소 지정
- 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시
- 레지스터 접근은 메모리보다 빠르다. ( 레지스터는 CPU 내에 있기 때문이다.)

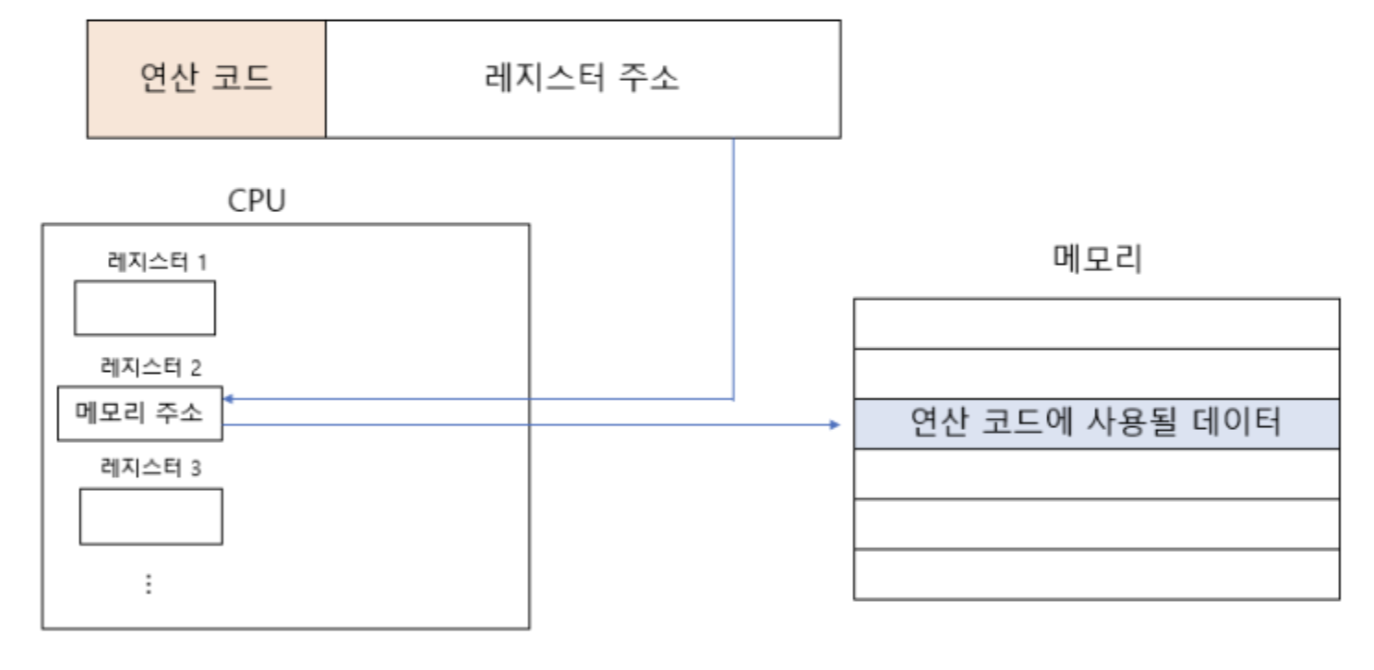
레지스터 간접 주소 지정
- 연산에 사용할 데이터를 메모리에 저장하고, 그 주소(유효 주소)를 저장한 레지스터를 오퍼랜드 필드에 명시
- 메모리 접근은 한 번 (레지스터 -> 메모리로 조회하기 때문)
'CS' 카테고리의 다른 글
| [컴퓨터 구조] 데이터 (0) | 2024.01.31 |
|---|
